File selection
sift provides various options to select which files you want to search. Some options provide overlapping functionality - the idea behind this is that less complex filtering options require less typing, while complex filtering selections are still possible.
The following table shows the different options:
| Option | Description | Examples |
|---|---|---|
-x, --ext
-X, --exclude-ext
|
Filter by file extension |
Only search in HTML files:
sift -x html pattern Exclude css and js files from search: sift -X css,js pattern |
-t, --type
-T, --exclude-type
|
Filter by file type |
Only search in Perl files (*.pl, *.pm, *.pod, *.t or a perl shebang on the first line):
sift -t perl pattern Exclude html and xml files: sift -T html,xml pattern |
--path
--exclude-path
|
Filter by full path |
Only search in files from March 2015:
sift --path '2015-03-\d\d/.*' pattern Exclude files form March 2015: sift --exclude-path '2015-03-\d\d/.*' pattern |
--files
--exclude-files
|
Filter by file name |
Only search in files matching a classic GLOB pattern:
sift --files 'crypto*.c' pattern Exclude files matching a classic GLOB pattern: sift --exclude-files 'crypto*.c' pattern |
--dirs
--exclude-dirs
|
restrict recursion to specific directories |
Only recurse into 'src' directories:
sift --dirs 'src' Do not recurse into '.git' directories: sift --exclude-dirs '.git' |
You can also use the file condition options to select which files you want to show matches for (depending on the content of the file).
Example: a collection of files with system health information, containing log messages and a status field.
If you want to search for lines starting with "log:", but only show them if the file contains "status: error",
you could use something like this:
sift --file-matches 'status: error' '^log:'
Data Extraction
sift was designed with real-world problems in mind. The following examples show some solutions to problems posted in forums/blogs/etc.
Sample data:
<FakeRecord> <RecordId>12345</RecordId> <ReqNumber>A1057</ReqNumber> <SubCode>8474</SubCode> <MasterCell>A14</MasterCell> <Serial>019284747</Serial> </FakeRecord>Source: http://code.scottshipp.com/2013/06/27/easily-extract-data-from-xml-using-grep-and-awk/
The quite complicated grep+awk combination to extract the RecordId
grep 'RecordId' myXmlFile.xml | awk -F">" '{print $2}' | awk -F"<" '{print $1}'
can be replaced with this:
sift '<RecordId>(\d+)' --replace '$1' myXmlFile.xml
Sample data:
<?xml version="1.0"?> <catalog> <book id="bk101"> <author>Gambardella, Matthew</author> <title>XML Developer's Guide</title> <genre>Computer</genre> <price>44.95</price> <publish_date>2000-10-01</publish_date> <description>An in-depth look at creating applications with XML.</description> </book> <book id="bk102"> <author>Ralls, Kim</author> <title>Midnight Rain</title> <genre>Fantasy</genre> <price>5.95</price> <publish_date>2000-12-16</publish_date> <description>A former architect battles corporate zombies, an evil sorceress, and her own childhood to become queen of the world.</description> </book> ...Source: http://www.unix.com/shell-programming-and-scripting/131881-read-content-between-xml-tags-awk-grep-awk-what-ever.html
sift can be used to extract multiline values:
sift -m '<description>(.*?)</description>' books.xml
The extracted data can easily be transformed to match a desired format:
sift -m '<description>(.*?)</description>' books.xml --replace 'description="$1"'
Result:
description="An in-depth look at creating applications with XML."
description="A former architect battles corporate zombies,
an evil sorceress, and her own childhood to become queen
of the world."
Extract the author of the book with id 'bk102':
sift -m '<book id="bk102">.*?</book>' books.xml | sift '<author>(.*?)</author>' --replace '$1'
or
sift -m '<book id="bk102">.*?<author>(.*?)</author>' books.xml --replace '$1'
or (using conditions and limiting results to one match)
sift '<author>(.*?)</author>' --preceded-by bk102 --limit 1 --replace '$1' books.xml
Using Conditions
Conditions allow more complex queries, e.g. to only show matches "that are preceded by X" or "if the file also contains Y".
An example usage are code audits, where one might want to search for specific insecure code patterns.
The
"Damn Vulnerable Web App (DVWA)"
is a demo application with many vulnerabilities to teach web application security. When searching for SQL injection vulnerabilities, we might look for the PHP function mysql_query():
sift mysql_query DVWA
This leads to many results, containing false positives:
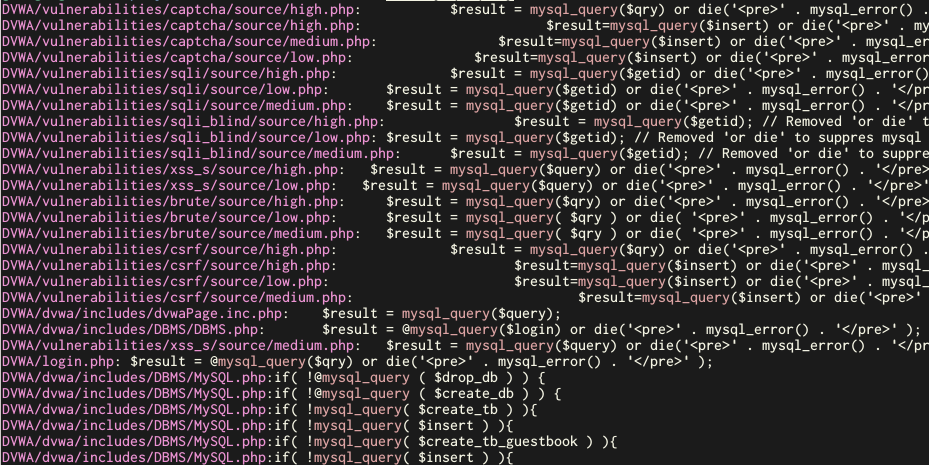
Using conditions, we can search for calls to mysql_query() that
- are preceded by $_GET or $_POST within a few lines, i.e. user provided data is being processed
- is not preceded by a call to an escape function like mysql_real_escape_string() to prevent SQL injection
sift mysql_query DVWA --preceded-within "5:_(GET|POST)" --not-preceded-by escape
Now we are left with three results, and the path names show that this was a good approach.

Performant data processing
Dimitri Roche published an interesting language comparision for an ETL (extract, transform, load) task.
The main goal was to compare the implementations while performance was not too important. It should be noted that all implementations used a map-reduce approach.
The task was to extract all tweets mentioning 'knicks' from a large dataset (about 40M record / 1 GB) and aggregate them based on the neighborhood of origin.
You can read the full blog post here:
http://www.dimroc.com/2014/09/29/etl-language-showdown/
The best performance was achieved with a solution in Ruby (40s) while the Go solution took about 63 seconds to finish.
sift can be used to perform this task easily - this example also shows its flexibility and how to optimize for performance.
A typical approach might be to solve this with one complex regular expression for sift (and some unix tools):
sift -i --no-filename '^\d+\s+([\w-]+).*knicks' --replace '$1' | sort | uniq -c | sort -nr | head
It takes about 47 seconds. While this is not bad, there is much room for improvement.
Searching for simple strings with sift is very fast due to optimizations in the used algorithms and implementations.
This task can be improved by filtering the data for lines containing 'knicks' first and then using the complex regular expression on the results only:
sift -i --no-filename knicks . | sift -i '\d+\s+([\w-]+).*knicks' --replace '$1' | sort | uniq -c | sort -nr | head
This takes about 1 second - sift processed 40 million records / 1 GB of data in just one second.
Log file search
sift can directly process .gz files - you can search through gzipped and normal logfiles at the same time with one call to sift.
I used about 200 dns log files for this performance test:
grep sift-tool.org queries.log queries.log-20141121; zgrep sift-tool.org queries.log*.gz
(1.466 seconds)
sift -z sift-tool.org queries*
(0.230 seconds)
sift is 6x faster and much easier to use.